# Background
卷积神经网络[1]主要使用在图像和视频分析的各种任务上,比如图像分类、人脸识别、图像分割上,其准确率远超其他的神经网络模型。基于卷积神经网络架构的模型在计算机视觉领域中已经占主导地位,当今几乎所有的图像识别、目标检测或语义分割相关的学术竞赛和商业应用都以这种方法为基础。
卷积神经网络最早出现是用来处理图像信息,在使用以往的全连接前馈网络处理图像时,往往是将图像数据展平成一维向量,再将数据送入一个全连接的多层感知机中。这样处理图像会存在以下两个问题:
- 参数太多:如果输入图像大小为 100×100×3,在全连接前馈网络中,第一个隐藏层的每个神经元与输入层都有 100×100×3=30000 个互相独立的连接,每个连接涉及到一个权重,值得注意的是,这还是一张很小的图片。随着隐藏层的神经元数目增多,参数的规模会急剧增大,同时使用全连接前馈神经网络来训练是十分低效的,且容易产生过拟合。
- 图片的局部不变性:自然图像中的物体都具有局部不变的特性,即图片的语义信息不会随着物体的平移,选择,缩放等操作而被影响。全连接前馈神经网络很难提取这些局部不变的特性。
卷积神经网络的灵感[2]来自于动物视觉皮层组织的神经连接方式。单个神经元只对有限区域内的刺激作出反应,不同神经元的感知区域相互重叠从而覆盖整个视野。
# Related knowledge
# LeNet-5
# AlexNet
# VGG
# NIN
# GoogLeNet
# Introduction
在 2014 年的 ImageNet 图像识别挑战赛中,一个名叫 GoogLeNet[3] 的网络架构大放异彩。 GoogLeNet 吸收了 NiN 中串联网络的思想,并在此基础上做了改进。
在卷积网络中,如何设置卷积核大小是一个十分关键的问题。毕竟,以前流行的网络使用小到,大到 的卷积核。对此,在我们设计卷积网络时,选择怎么样的卷积核的有效合适的呢? GoogLeNet 则认为不同大小的卷积核对于信息的提取作用是不同的,固使用不同大小的卷积核组合是有利的(增加网络宽度)。GoogLeNet 引入 Inception 模块,每个 Inception 模块是由多个不同大小的卷积层和池化层组合而成的,它通过不同窗口形状的卷积层和最大汇聚层来并行抽取信息,GoogLeNet/Inception 网络则是由多个 Inception 模块拼接而成。Inception 网络有多个版本(Inception V2、Inception V3、Inception V4 等),其中最早的 Inception v1 就是非常著名的 GoogLeNet,其在 2014 年的 ImageNet 图像识别挑战赛中获得了冠军。
# Inception V1
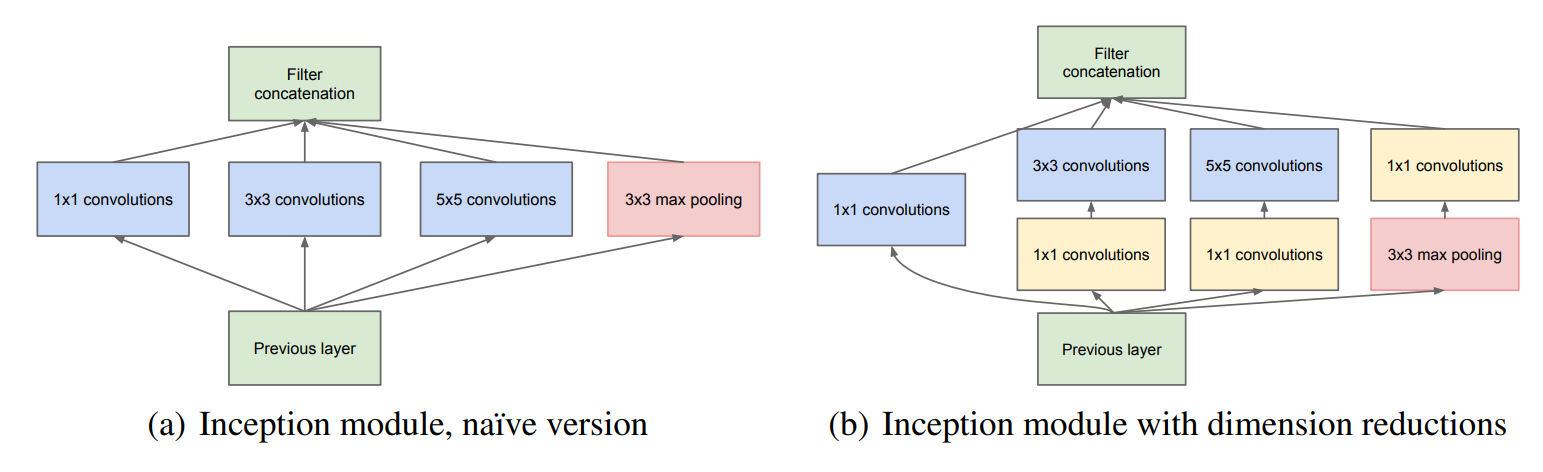
Inception v1 模块[4]由四组平行的特征抽取方式组合而成,分别是 的卷积和 的最大池化层,如图(a)。同时为了较少模型参数和计算的复杂度,分别在 的卷积下方和最大池化层的上方引入了一个 的卷积,以此来减少通道数,如图(b)。
卷积核的作用:
- 特征提取(提取与空间无关的特性信息)
- 降低通道数(压缩降维),以此达到减少模型参数与计算复杂度。这种思想称为 Pointwise Conv(PW)
# InceptionV1 Coding
import torch | |
import torch.nn as nn | |
class BasicConv2d(nn.Module): | |
def __init__(self, in_channels, out_channels, **kwargs): | |
super(BasicConv2d, self).__init__() | |
self.conv = nn.Conv2d(in_channels, out_channels, **kwargs) | |
self.relu = nn.ReLU() | |
def forward(self, x): | |
x = self.conv(x) | |
x = self.relu(x) | |
return x | |
class InceptionV1(nn.Module): | |
def __init__(self, in_channels, channels1, channels2, channels3, channels4): | |
super(InceptionV1, self).__init__() | |
# 线路 1,单 1x1 卷积层 | |
self.branch1 = BasicConv2d(in_channels, channels1, kernel_size=1) | |
# 线路 2,1x1 卷积层后接 3x3 卷积层 | |
self.branch2 = nn.Sequential( | |
BasicConv2d(in_channels, channels2[0], kernel_size=1), | |
BasicConv2d(channels2[0], channels2[1], kernel_size=3, padding=1) | |
) | |
# 线路 3,1x1 卷积层后接 5x5 卷积层 | |
self.branch3 = nn.Sequential( | |
BasicConv2d(in_channels, channels3[0], kernel_size=1), | |
BasicConv2d(channels3[0], channels3[1], kernel_size=5, padding=2) | |
) | |
# 线路 4,3x3 最大汇聚层后接 1x1 卷积层 | |
self.branch4 = nn.Sequential( | |
nn.MaxPool2d(kernel_size=3, stride=1, padding=1), | |
BasicConv2d(in_channels, channels4, kernel_size=1) | |
) | |
def forward(self, x): | |
branch1 = self.branch1(x) | |
branch2 = self.branch2(x) | |
branch3 = self.branch3(x) | |
branch4 = self.branch4(x) | |
outputs = [branch1, branch2, branch3, branch4] | |
return torch.cat(outputs, dim=1) |
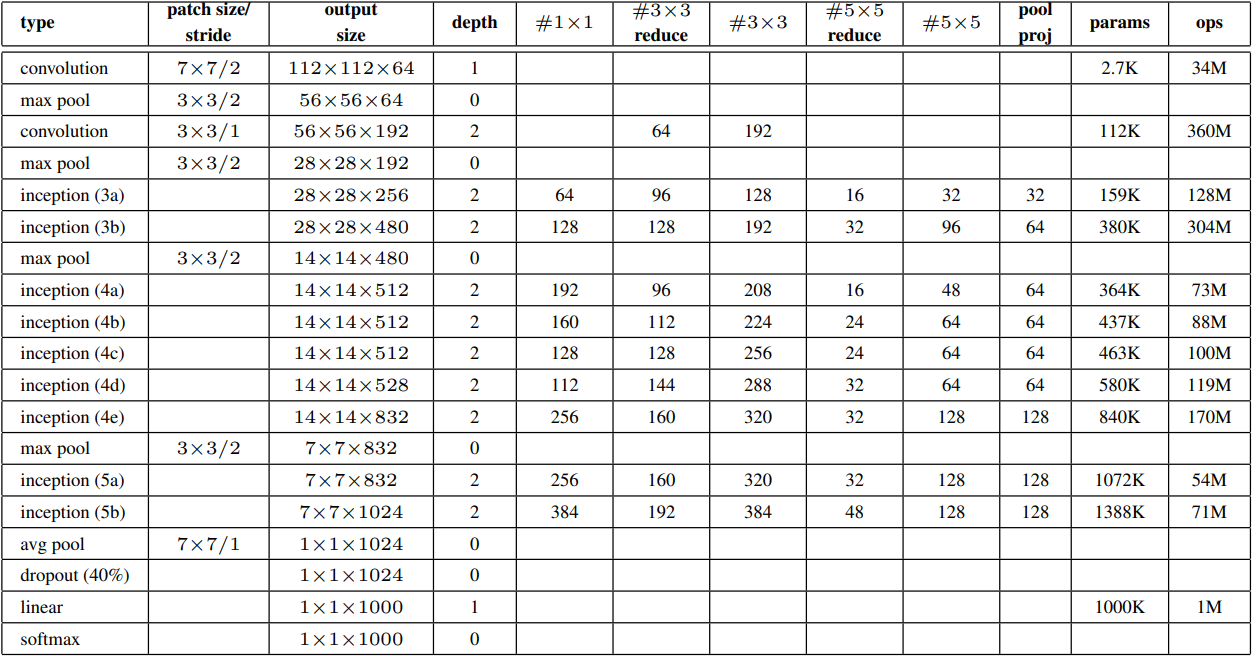
如下图是 GoogLeNet 架构,其由 9 个 Inception v1 模块和 5 个池化层和一些全连接层组成,总共 22 层网络,大致可以分成如下五个模块:
[
- 模块一:一个卷积层; 个通道、 卷积层
- 模块二:两个卷积层;64 个通道、1×1 卷积层和 192 通道、3×3 卷积层
- 模块三:两个 Inception 块:
- 第一个 Inception 块的输出通道数为,四个路径之间的输出通道数量比为
- 第二个 Inception 块的输出通道数为,四个路径之间的输出通道数量比为。
- 模块四:五个 Inception 块:
- 第一个 Inception 块的输出通道数为,四个路径之间的输出通道数量比为
- 第二个 Inception 块的输出通道数为,四个路径之间的输出通道数量比为
- 第三个 Inception 块的输出通道数为,四个路径之间的输出通道数量比为
- 第四个 Inception 块的输出通道数为,四个路径之间的输出通道数量比为
- 第五个 Inception 块的输出通道数为,四个路径之间的输出通道数量比为
- 模块五:两个 Inception 块:
- 第一个 Inception 块的输出通道数为,四个路径之间的输出通道数量比为
- 第二个 Inception 块的输出通道数为,四个路径之间的输出通道数量比为
需要注意的是,第五模块的后面紧跟输出层,该模块同 NiN 一样使用全局平均汇聚层,将每个通道的高和宽变成 1。 最后我们将输出变成二维数组,再接上一个输出个数为标签类别数的全连接层。
同时,对于其中 Inception 块的通道数分配之比是在 ImageNet 数据集上通过大量的实验得来的。
# GoogLeNet Coding
import torch.nn.functional as F | |
class GlobalAvgPool2d(nn.Module): | |
def __init__(self): | |
super(GlobalAvgPool2d, self).__init__() | |
def forward(self, x): | |
# 池化窗口形状等于输入图像的形状 | |
return nn.functional.avg_pool2d(x, kernel_size=x.size()[2:]) | |
class GoogLeNetModelV1(nn.Module): | |
def __init__(self, num_class, aux_classifier=False): | |
super(GoogLeNetModelV1, self).__init__() | |
self.aux_classifier = aux_classifier | |
# 模块一 | |
self.b1 = nn.Sequential( | |
BasicConv2d(1, 64, kernel_size=7, stride=2, padding=3), | |
nn.MaxPool2d(kernel_size=3, stride=2, padding=1) | |
) | |
# 模块二 | |
self.b2 = nn.Sequential( | |
nn.Conv2d(64, 64, kernel_size=1), | |
nn.Conv2d(64, 192, kernel_size=3, padding=1), | |
nn.MaxPool2d(kernel_size=3, stride=2, padding=1) | |
) | |
# 模块三 | |
self.b3 = nn.Sequential( | |
InceptionV1(192, 64, (96, 128), (16, 32), 32), | |
InceptionV1(256, 128, (128, 192), (32, 96), 64), | |
nn.MaxPool2d(kernel_size=3, stride=2, padding=1) | |
) | |
# 模块四 | |
self.b4 = nn.Sequential( | |
InceptionV1(480, 192, (96, 208), (16, 48), 64), | |
InceptionV1(512, 160, (112, 224), (24, 64), 64), | |
InceptionV1(512, 128, (128, 256), (24, 64), 64), | |
InceptionV1(512, 112, (144, 288), (32, 64), 64), | |
InceptionV1(528, 256, (160, 320), (32, 128), 128), | |
nn.MaxPool2d(kernel_size=3, stride=2, padding=1) | |
) | |
# 模块五 | |
self.b5 = nn.Sequential( | |
InceptionV1(832, 256, (160, 320), (32, 128), 128), | |
InceptionV1(832, 384, (192, 384), (48, 128), 128), | |
GlobalAvgPool2d() | |
) | |
# 全连接层 | |
self.fc = nn.Linear(1024, num_class) | |
def forward(self, x): | |
batch_size = x.size(0) | |
x = self.b1(x) | |
x = self.b2(x) | |
x = self.b3(x) | |
x = self.b4(x) | |
x = self.b5(x) | |
x = x.view(batch_size, -1) | |
x = self.fc(x) | |
x = F.log_softmax(x, dim=1) | |
return x |
# Inception V2
# ResNet
# 参考文献
[邱锡鹏。神经网络与深度学习 [M]. 机械工业出版社,2020](nndl.github.io/nndl-book.pdf at master · nndl/nndl.github.io · GitHub) ↩︎
卷积神经网络 - 维基百科,自由的百科全书 ↩︎
[C. Szegedy et al., "Going deeper with convolutions," 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 2015, pp. 1-9, doi: 10.1109/CVPR.2015.7298594](Going deeper with convolutions | IEEE Conference Publication | IEEE Xplore) ↩︎
[(Zhang A, Lipton Z C, Li M, et al. Dive into deep learning[J]. arXiv preprint arXiv:2106.11342, 2021)](nndl.github.io/nndl-book.pdf at master · nndl/nndl.github.io · GitHub) ↩︎